Cloud & Agentic Infrastructure
Cloud-native foundations and agentic pipeline orchestration on AWS, GCP, and Azure, so your AI products run reliably, scale automatically, and cost what they should.
AI products fail in production for infrastructure reasons, not model reasons.
The model works in the notebook. The demo runs fine. But in production, agentic workflows time out, vector search latency spikes unpredictably, and nobody knows which prompt version caused the regression two weeks ago. Most teams are running AI on infrastructure designed for traditional web apps, and wondering why it's unreliable. The fix isn't a better model. It's an infrastructure layer built specifically for the way AI workloads actually behave.
Building an AI product is only half the job. The teams that ship reliably are not just good at models, they are good at infrastructure: agent pipelines that run on a schedule, recover from failure, and route intelligently between tools; observability that surfaces prompt drift before a customer notices; CI gates on eval scores instead of test coverage. We build that layer, cloud-native foundations on AWS, GCP, and Azure, vector database deployments (pgvector, Pinecone, Qdrant, Weaviate), agent orchestration on LangGraph and Temporal, and the cost and latency controls that keep your AI bill predictable.
Capabilities
Cloud-native AI deployments
AWS, GCP, and Azure environments right-sized for AI: GPU instances for fine-tuning, serverless inference endpoints, auto-scaling policies that match token throughput, not just HTTP requests.
Agentic pipeline orchestration
LangGraph, Temporal, and Prefect workflows that handle multi-step agent execution, tool-calling loops, retries, and state persistence. Built to recover gracefully from LLM failures and partial completions.
Vector database infrastructure
Qdrant, Weaviate, and pgvector deployments optimised for retrieval latency and embedding freshness. Indexing pipelines, namespace management, and the monitoring that surfaces staleness before users notice.
AI observability and evaluation
Prompt versioning, output logging, and continuous evaluation against your golden dataset. Datadog for infra metrics, RAGAS and Braintrust for model quality, wired together into a single operational picture.
CI/CD for AI workloads
Model promotion pipelines that gate on eval scores, not just test coverage. Canary deployments for new prompt versions, automated rollback on quality regression, and the audit trail that satisfies enterprise procurement.
Cost and latency optimisation
Model routing between providers based on latency and cost targets, caching strategies for repeated queries, and the infrastructure changes that cut your monthly AI bill without degrading output quality.
How we build it
Tools and technologies we use in this practice, chosen for fit, not familiarity.
Our process
Consistent across every engagement, adapted to your constraints, not the other way around.
AI infra audit and target design
We map your current stack, model providers, vector stores, pipeline triggers, and observability gaps. Output: a written architecture decision record with a prioritised list of infra risks and a proposed target state.
Foundation and pipeline build
Cloud environments, agentic orchestration scaffolding, and vector DB setup deployed in two-week phases. Each phase ships something to production, we don't hold back until the full architecture is complete.
Observability and handoff
Dashboards, eval pipelines, and runbooks your team owns. We consider the engagement done when your engineers can deploy a new agent, monitor its quality, and roll it back, without us in the loop.
Questions teams ask before they start
What is cloud agentic infrastructure?
Cloud agentic infrastructure is the set of cloud-native services, orchestration layers, data pipelines, and security controls that underpin AI agent systems in production. It covers compute for inference, vector databases, message queues for agent coordination, observability tooling, and the networking and IAM policies that keep agentic workloads secure and compliant at scale.
Which cloud providers does 7code support for agentic infrastructure?
7code designs and deploys agentic infrastructure on AWS, Google Cloud Platform, and Microsoft Azure. For clients with existing cloud commitments, 7code works within the incumbent provider. Multi-cloud and hybrid architectures — where sensitive model inference stays on-premises while orchestration runs in the cloud — are supported for regulated industries.
Why does AI require specialised cloud infrastructure?
AI workloads have fundamentally different profiles from conventional applications: they require GPU or TPU compute for inference, low-latency access to vector databases, high-throughput pipelines for data ingestion, and sophisticated observability to monitor model behaviour over time. Standard cloud setups are inadequate — purpose-built agentic infrastructure reduces cost, latency, and operational risk significantly.
How does 7code optimise AI infrastructure for latency and cost?
7code uses a combination of model quantisation, intelligent caching of frequent LLM responses, spot/preemptible compute for batch inference, auto-scaling groups calibrated to actual traffic patterns, and CDN-layer caching for static AI outputs. Infrastructure is right-sized during a two-week Architecture Review before build, preventing over-provisioning from day one.
How does 7code ensure agentic infrastructure scales with demand?
7code designs infrastructure with horizontal scalability as a first principle: stateless inference services behind load balancers, Kubernetes-managed autoscaling, queue-based decoupling of agent tasks from inference compute, and database sharding strategies for vector stores. Load and stress testing is conducted before go-live; scaling thresholds are documented so clients can manage growth without emergency rearchitecting.
How does 7code handle security and compliance for AI infrastructure?
Security is embedded at design time: IAM roles follow least-privilege principles, all data at rest and in transit is encrypted, network segmentation isolates AI workloads from general systems, and audit logs capture all model interactions. For EU clients, infrastructure is GDPR-compliant by design. Regulated sectors receive additional controls aligned to sector-specific frameworks.
What monitoring and observability does 7code build into AI infrastructure?
Standard observability includes: model latency and error rate dashboards, token usage and cost tracking per agent, anomaly detection on output distributions, human-in-the-loop review queues for flagged outputs, and alerting for infrastructure events. 7code typically delivers observability via Grafana, Datadog, or AWS CloudWatch depending on the client’s existing tooling.
How does 7code support migration from legacy infrastructure to cloud agentic architecture?
7code conducts a Legacy Infrastructure Assessment to map existing systems, identify integration points, and define a phased migration path that keeps current operations running throughout. Migration is staged: infrastructure is rebuilt in parallel, workloads are migrated incrementally with rollback capability, and the legacy system is decommissioned only after the new architecture is validated in production.
Projects using this service
Self-serve AI analytics platform for unstructured text

AI-powered news aggregator for the MENA region
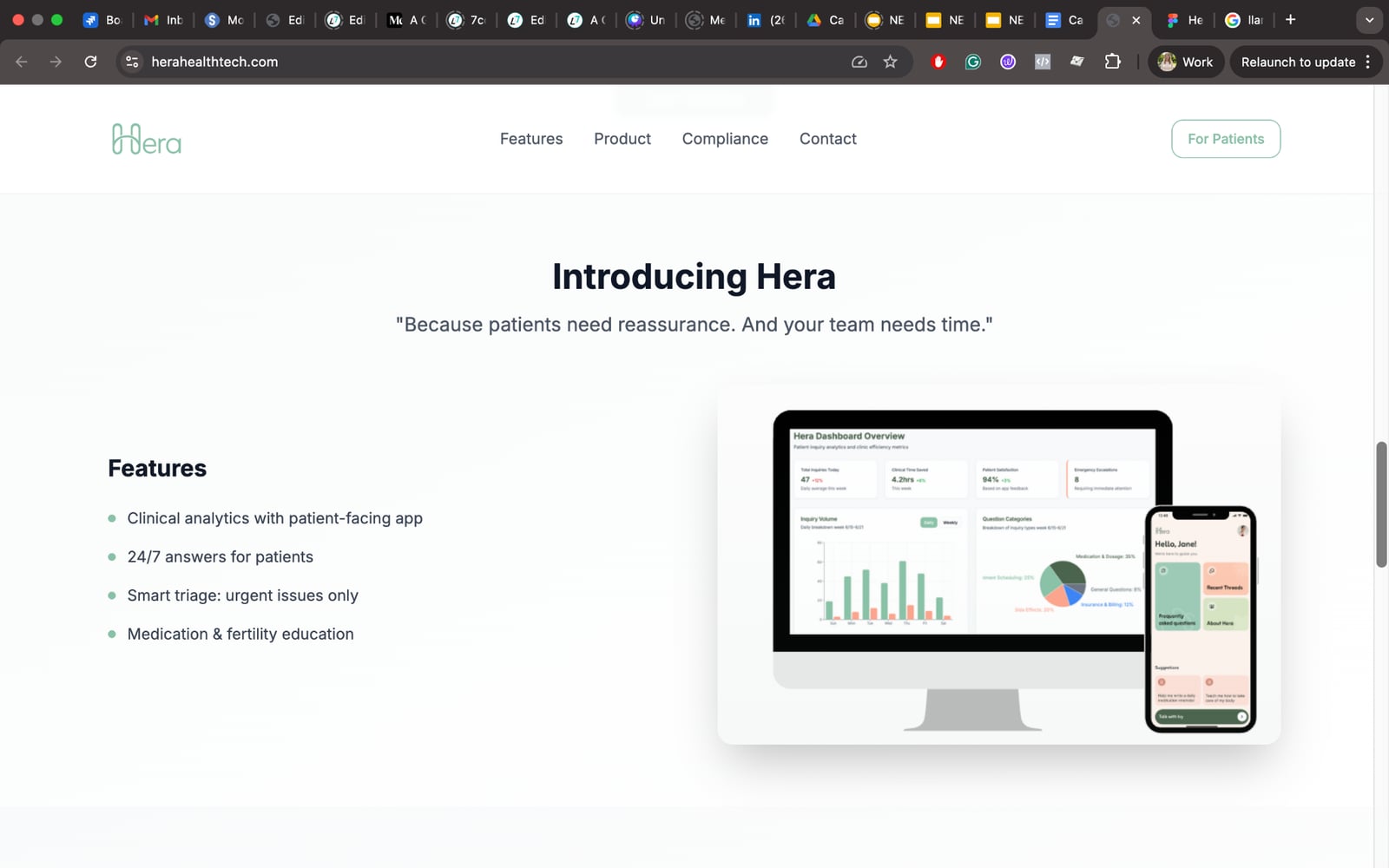
AI-powered patient-support app for fertility clinics
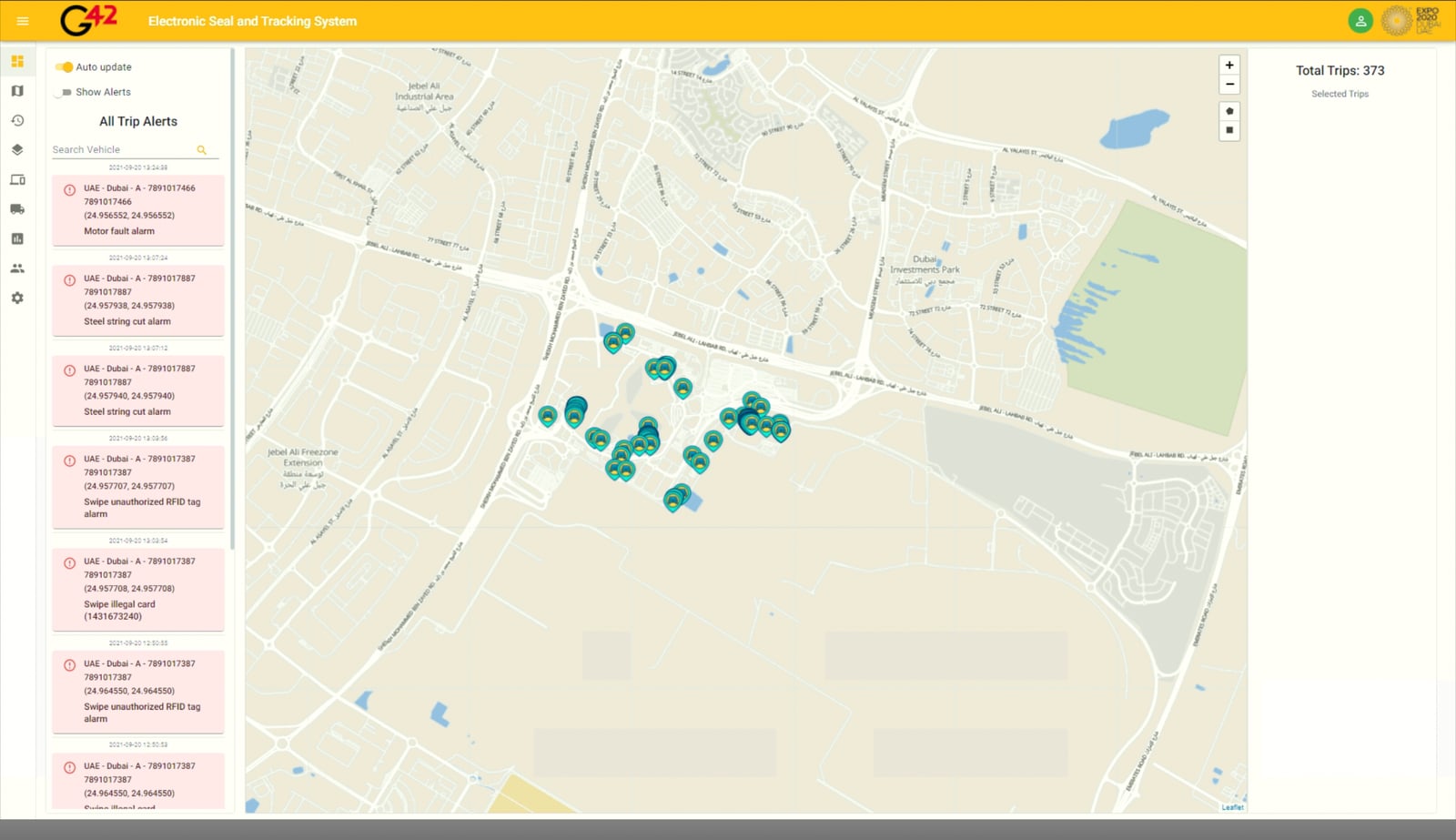
Real-time fleet tracking platform for EXPO 2020 Dubai
Ready to build your next product?
Tell us about your project. We'll respond within one business day with next steps.
We use cookies
We use essential cookies for the site to work, and analytics cookies (Google Analytics) to understand how you use it. Cookie Policy.